Lab 04: DDPG
Background: Understanding DDPG
Deep Deterministic Policy Gradient (DDPG) extends the ideas behind DQN to environments with continuous action spaces — settings where the agent must output a real-valued action (e.g., a force or torque) rather than choosing from a discrete set.
Before diving into the code, read the OpenAI Spinning Up page on DDPG: https://spinningup.openai.com/en/latest/algorithms/ddpg.html
Why do we need DDPG?
Recall that DQN works by learning \(Q(s, a)\) for every discrete action \(a\) and then selecting \(\arg\max_a Q(s,a)\). When the action space is continuous, this \(\arg\max\) becomes an intractable optimization problem — you cannot simply enumerate all possible actions. DDPG sidesteps this by learning a deterministic policy \(\mu_\theta(s)\) that directly maps states to actions, while simultaneously learning a Q-function \(Q_\phi(s, a)\) that evaluates how good those actions are.
Key components of DDPG
DDPG introduces an actor-critic architecture with four networks:
| Network | Role | Input | Output |
|---|---|---|---|
| Actor \(\mu_\theta(s)\) | Selects actions | State \(s\) | Continuous action \(a\) |
| Critic \(Q_\phi(s, a)\) | Evaluates state-action pairs | State \(s\) + Action \(a\) | Scalar Q-value |
| Target Actor \(\mu_{\theta'}(s)\) | Stabilizes actor targets | State \(s\) | Action (for computing targets) |
| Target Critic \(Q_{\phi'}(s, a)\) | Stabilizes critic targets | State \(s\) + Action \(a\) | Q-value (for computing targets) |
The critic is updated by minimizing the Bellman error, similar to DQN:
\[L_Q = \mathbb{E}\left[\left(Q_\phi(s, a) - \left(r + \gamma Q_{\phi'}(s', \mu_{\theta'}(s'))\right)\right)^2\right]\]The actor is updated by performing gradient ascent on the expected Q-value:
\[\nabla_\theta J \approx \mathbb{E}\left[\nabla_a Q_\phi(s, a)\big|_{a=\mu_\theta(s)} \cdot \nabla_\theta \mu_\theta(s)\right]\]Intuitively, the actor adjusts its policy in the direction that the critic says will increase the Q-value.
Exploration in continuous spaces
Since the policy is deterministic, DDPG explores by adding noise to the actor’s output during training:
\[a = \mu_\theta(s) + \epsilon, \quad \epsilon \sim \mathcal{N}(0, \sigma)\]This noise is decayed over the course of training so the agent transitions from broad exploration to fine-grained exploitation. Getting the noise schedule right is an important practical consideration, as you will discover in this lab.
Implementation
Your task is to adapt the DQN code from the previous demo to implement DDPG, and use it to solve the MountainCarContinuous-v0 environment:
env = gym.make("MountainCarContinuous-v0", render_mode="rgb_array")
n_state = int(np.prod(env.observation_space.shape))
n_action = int(np.prod(env.action_space.shape))
print("# of state", n_state)
print("# of action", n_action)
Below is a summary of the key modifications you need to make.
1. Add an Actor Network
Introduce a second neural network (along with its target copy) that serves as the policy function (the “actor”). This network takes the observation obs as input and outputs a continuous action as an np.array.
- Use
nn.Tanh()as the final activation to bound the output to \([-1, 1]\), and scale byself.act_limto match the environment’s action range. - Create separate Adam optimizers for the actor and critic — they are trained with different loss functions, so they must not share an optimizer.
2. Modify the Critic (Q-Network)
Change the q_net so that it takes the concatenation of [state, action] as input and outputs a single scalar Q-value.
- This means updating every place where you call
self.q_net— both in the critic loss computation and in the actor loss computation. - Here is how to compute the target Q-value:
q_input = torch.cat( [next_obs, self.act_lim * self.target_act_net(next_obs)], axis=1) y = reward + self.gamma * (1 - done) * \ self.target_q_net(q_input).squeeze() - To compute the actor loss, remember that we want to maximize the Q-value of the actor’s chosen actions. Since PyTorch optimizers minimize, negate the Q-value:
q_input = torch.cat([obs, self.act_lim * self.act_net(obs)], axis=1) loss_act = -self.q_net(q_input).mean()
Target Network Synchronization
Initialize target networks as deep copies of the online networks using copy.deepcopy. During training, periodically sync the target networks by copying the online network weights (e.g., every 5 update steps):
self.target_q_net.load_state_dict(self.q_net.state_dict())
self.target_act_net.load_state_dict(self.act_net.state_dict())
An alternative is Polyak averaging (soft update), where target weights are blended toward online weights every step: \(\theta' \leftarrow \tau\theta + (1-\tau)\theta'\) with a small \(\tau\) (e.g., 0.005). Either approach works; the reference solution uses periodic hard copy.
3. Replace Epsilon-Greedy with Gaussian Noise
Instead of \(\epsilon\)-greedy exploration (which only makes sense for discrete actions), add Gaussian noise to the actor’s output:
act += self.noise * np.random.randn(n_action)
act = np.clip(act, -self.act_lim, self.act_lim)
where self.noise is a hyperparameter controlling the exploration intensity. Always clip the noisy action to the valid range [-act_lim, act_lim] — without clipping, out-of-bound actions can cause environment errors or degrade learning.
Decay this noise after each episode (not each step):
if agent.noise > 0.005:
agent.noise -= (1/200)
4. Update the Replay Buffer
Store actions as FloatTensor (not LongTensor as in DQN) since actions are now continuous-valued.
5. Track Both Losses
Return two loss values from the update method: loss_q (critic loss) and loss_act (actor loss). Monitoring both is essential for debugging.
Comprehension Questions
Answer the following questions in your report. These are designed to test your understanding of the DDPG algorithm, not just your implementation.
Q1. In DDPG, the actor is updated by computing \(\nabla_\theta \mu_\theta(s)\) through the critic network \(Q_\phi(s, a)\). Explain why it is critical that we freeze the critic’s parameters (i.e., do not update them) when performing the actor’s gradient step. What would go wrong if we allowed gradients to flow into the critic during the actor update?
Q2. DDPG uses target networks that are slowly updated (either via periodic copying or Polyak averaging). Suppose you removed the target networks entirely and used the online actor and critic to compute the Bellman target directly. Describe, in concrete terms, why this would destabilize training. (Hint: think about what happens to the target \(y = r + \gamma Q_\phi(s', \mu_\theta(s'))\) when \(Q_\phi\) and \(\mu_\theta\) change after each gradient step.)
Experiment Questions
Answer the following based on your experiments:
-
How does the initial noise scale
self.noiseimpact training and performance? Run multiple experiments with different noise settings and plot the learning curves to support your answer. -
(Open-ended) What is the major downside of DDPG based on your understanding and/or observations during this lab?
Deliverables and Rubrics
| Points | Requirement |
|---|---|
| 60 pts | PDF report (exported from Jupyter notebook) and Python source code. The report must include at least the reward curve over training episodes. |
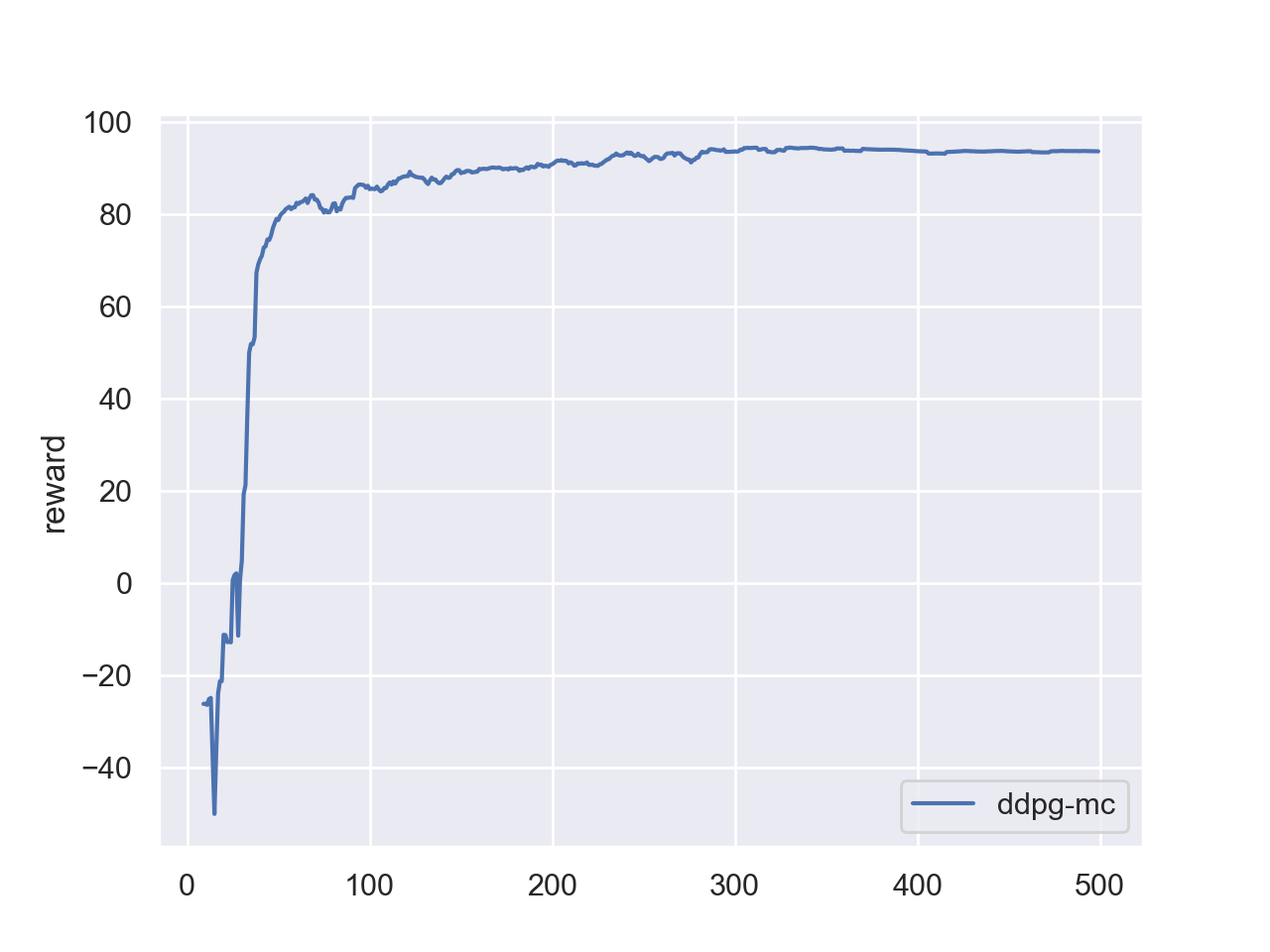
| 15 pts | Your implementation achieves a desirable result. A correct implementation should reach a mean reward above 80 within 300 episodes. (See reference plots below.) |
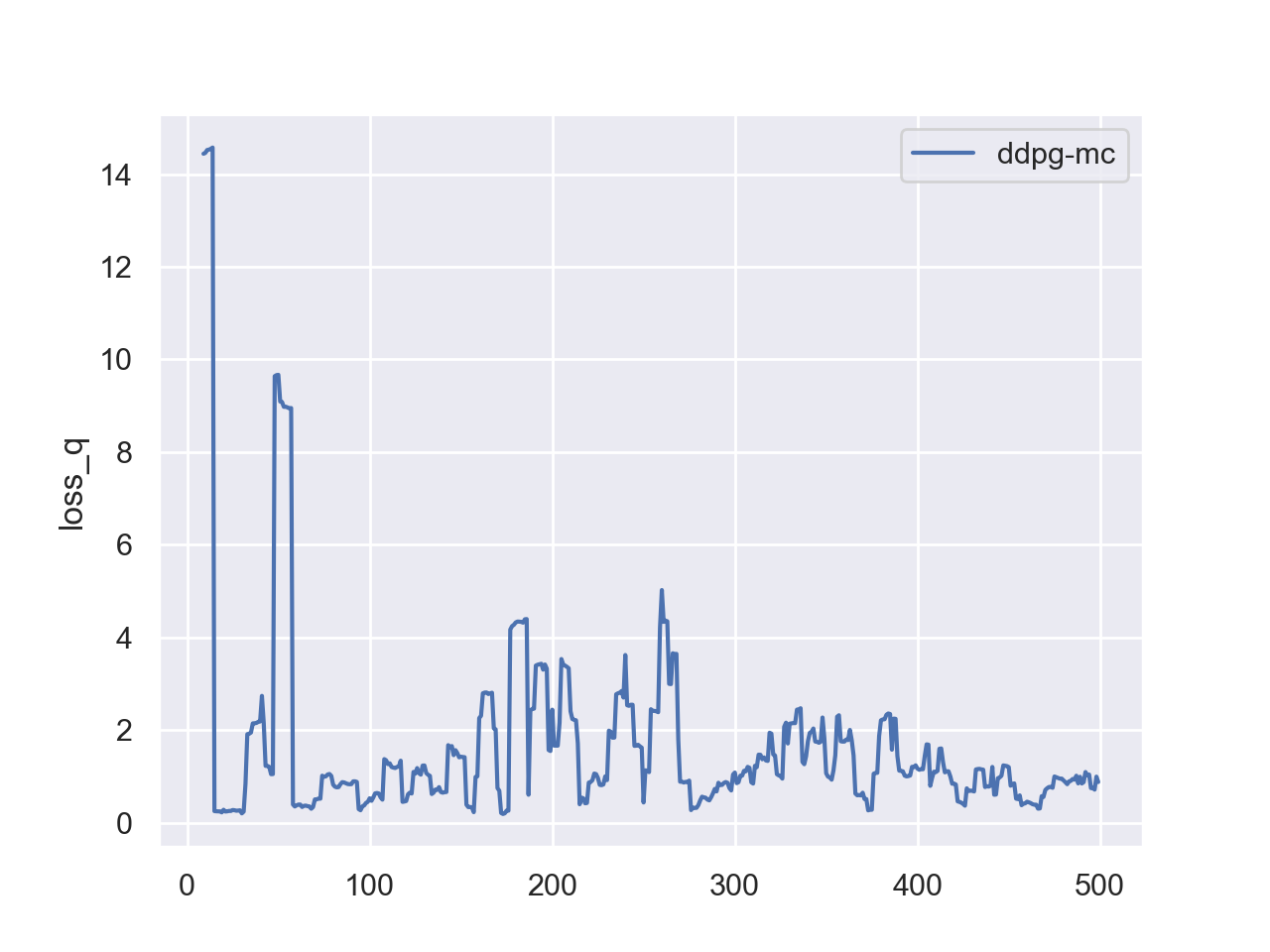
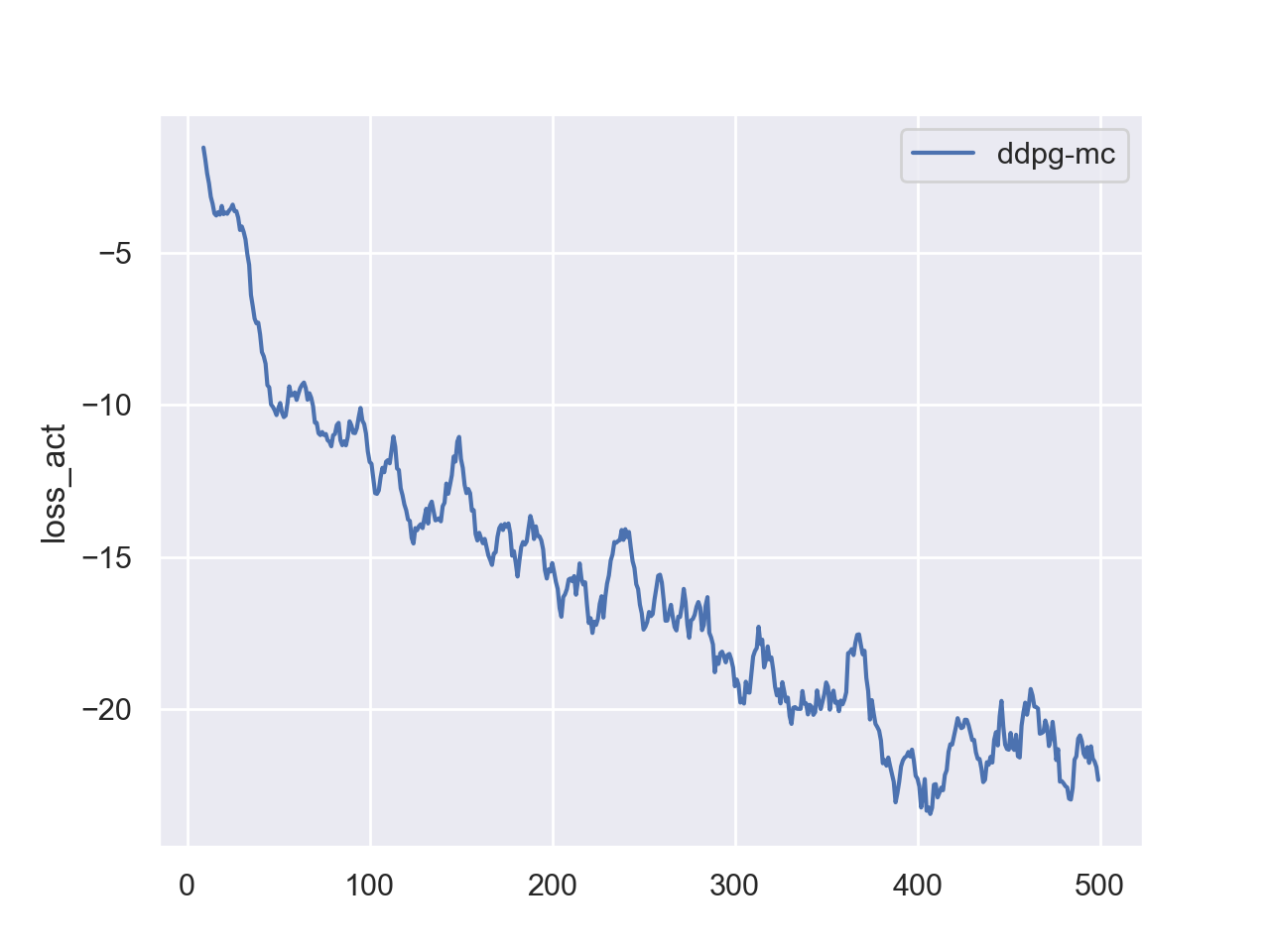
| 15 pts | Stability analysis. DDPG can be unstable — sometimes it learns quickly, and other times it gets stuck and never improves. Run your code with different random seeds to reproduce both successful and failed training runs. In the failure cases, you will likely observe that loss_act remains positive and the agent does not improve, indicating the replay buffer is dominated by poor experiences from unsuccessful exploration. Propose possible ways to mitigate this issue, implement at least one, and show the result. |
| 10 pts | Reasonable answers to the comprehension questions and experiment questions above. |
Debugging Tips
-
Monitor both losses.
loss_qshould be positive (it is an MSE loss).loss_actshould be negative — it represents the negated expected Q-value, so a negative value means the critic is assigning high value to the actor’s chosen actions. A persistently positiveloss_actindicates that the replay buffer is filled with unsuccessful experiences, leading the critic to assign low Q-values everywhere. -
Also see the Debugging Guide for a systematic troubleshooting checklist.
Reference Network Architecture
self.q_net = nn.Sequential(
nn.Linear(n_state + n_action, 400),
nn.ReLU(),
nn.Linear(400, 300),
nn.ReLU(),
nn.Linear(300, 1)
)
self.act_net = nn.Sequential(
nn.Linear(n_state, 400),
nn.ReLU(),
nn.Linear(400, 300),
nn.ReLU(),
nn.Linear(300, n_action),
nn.Tanh()
)
Reference Hyperparameters
- Initial exploration noise:
2 - Noise decay:
1/200per episode (decayed until noise reaches0.005)
Reference Training Loop
Feel free to use the following training loop as a starting point. Adapt the agent variable to your own policy class.
loss_q_list, loss_act_list, reward_list = [], [], []
update_freq = 10
n_step = 0
loss_q, loss_act = 0, 0
for i in tqdm(range(500)):
obs, _ = env.reset()
rew = 0
while True:
act = agent(obs)
next_obs, reward, done, truncated, _ = env.step(act)
rew += reward
n_step += 1
agent.replaybuff.add(obs, act, reward, next_obs, done or truncated)
obs = next_obs
if len(agent.replaybuff) > 1e3 and n_step % update_freq == 0:
loss_q, loss_act = agent.update()
if done or truncated:
break
if i > 0 and i % 50 == 0:
run_episode(env, agent, True)
print("itr:({:>5d}) loss_q:{:>3.4f} loss_act:{:>3.4f} reward:{:>3.1f}".format(
i, np.mean(loss_q_list[-50:]),
np.mean(loss_act_list[-50:]),
np.mean(reward_list[-50:])))
if agent.noise > 0.005:
agent.noise -= (1/200)
loss_q_list.append(loss_q), loss_act_list.append(
loss_act), reward_list.append(rew)
Reference Training Curves